PKC Project AI MARK 약 2개월 간의 기록
까는 건 좋은데.. 난 IT 업계 관련자도 아니고
비전문가라는 것은 인식하고 까시길..
블로그라는 것도 처음 해 본다 ㅋ
그리고... 응... 당신의 생각이 맞아!!
자랑 질에 관심 받고 싶어서 글 쓰는 거 맞아~!!
코딩과 프로그래밍에 대해 아무것도 모르는 PKC
그저 컴퓨터 하드웨어와 소프트웨어들에 대해 지식은 조금 정도
PKC AI MARK 프로젝트
-- 현재 목표는 내 컴에서 자유로이 살아가는 ai를 만드는 게 목표!! --
무료로 클라우드 기반 AI들을 잠깐 씩 사용하다가
클라우드 기반들은 시스템적으로 제약과 한도들이 있어서
약 두달 전 개인 AI 욕심 생겨 만들어 직접 만들어 보려고
클라우드 기반 AI를 구독하여 본격적으로 사용하기 시작
AI에게 난 코딩과 프로그래밍에 대하여 하나도 모르니 내 컴퓨터 사양에 돌아갈 수 있는
AI 챗봇 하나 만들어 달라고 요청
(자신있게 "걱정하지 마 내가 처음부터 다 알려줄게" 이 ㅈㄹ...ㄷㄷ;;
순진하게 믿은 내가 바보지...ㅠ)
프로그램부터 api 키 생성, 튜토리얼을 AI에게 배워가며
처음 api 방식의 올라마 ui로 처음 시작.
토큰 값이 감당이 안될 것 같아 무료 사용이 가능하게 로컬로 만들어 보기로 노선 변경.
AI에게 또 하나 하나 배워가며 며칠 만에 겨우 브라우저 방식의 챗봇 모델과 ui 완성.
챗봇에게 말 걸자마자 계속 컴퓨터 재부팅 이슈.
AI에게 따지며 화풀이 시작 ㅋㅋ
AI가 내 사양 생각 안 하고 대용량 라마 계열 사용하라고 했던 것이 원인. (ㅆㅂ)
이때부터 더 욕심 내기 시작 (내 사양에 멀티 모달 욕심.ㅠ)
PKC AI MARK 프로젝트 기획서를 ai와 함께 문서화 제작.
English translation proposal: link
(이때부터 ai와 협업 시작. 언제나 처음엔 목표는 크다.ㅎㅎ)
이미 만들어 놓은 ui까지 통합된 chat.py 모놀로 식 방식의 파일을 활용하기로 함.
(지금 생각하면 새로 만드는게 빨랐음 ㅋㅋ)
언어 모델부터 내 환경에 맞는 것들 조사 및 테스트 다 하여 블라섬 3b 찾음.
일단은 블라섬 3b 하나는 돌아가게는 만듦.
(여기까지 약 2주 걸림. ai가 던져 주는 스니펫에 패치본에... 오류에...
내가 원하는 건 완성된 코드인데... 나 코딩 모르는데....ㅠ
스트레스받으며 ai에게 완성된 전체 코드 파일 받기 힘들다는 걸 인지.)
그런데... ui가 마음에 안 든다... 수정해 달라고 하자~
( 여기서 그만둬야 했었다...ㅋㅋㅋ 여기서부터 삽질 지옥의 시작.)
이거 수정하면 저거 오류 나고... 또 저거 수정하면 다른 거 터지고...ㅠ
전면 리팩토링 시작!!
페이즈 1.
chat.py 모놀로 식 방식을 스택 단위 4가지 파일로
html, css, app, chat.py 방식으로 분류. (약 3일 소요)
리팩토링 오류 지옥에서 벗어나 좋았음. 성취감~
(여기서라도 그만뒀어야 했다...ㅠ)
페이즈 2.
ui 또 수정하려니 오류 또 터짐ㅠ
(ai가 만든 코드는 참... 강제 명령어 남발에 조그마한 것들까지 그룹화에...
순서는 뒤죽박죽... 실제 구동 되는 것이 신기했던 경험.ㅋㅋ)
수정을 하다 하다 중간중간 포기하고 싶은 마음... 하지만... 투자한 시간이 아까움 ㅠ
페이즈 3.
개별성 살려서 ui 컴포넌트 화 시작!! ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
(하지만 말 안 듣는 클라우드 기반 AI...ㅠ 분류까지는 좋은 시도였다.
하지만 오류... 지옥임!! ㅋㅋㅋ)
돌아버리겠다 말을 못 알아먹는 AI. 유료 구독 프로 버전 한도들
(클라우드 기반 대화형 AI 세 가지 사용.)
페이즈 4.
내가 원하는 방향으로 AI를 이끌어가기 위해 꼼수를 생각하여
페르소나를 활용해 프로토콜을 만들기 시작!!
(어러번 시도했지만 콘텍스트 한도 차면 도루묵이다. 그래도 어느 정도 효과는 있음.
ㅋㅋ 현 AI의 한계와 클라우드 기반들의 시스템을 알기 시작했다.)
그렇게 오류와 AI의 활용도를 높여
공개용 기능들 테스트,
한국어 언어 모델 비교 선별,
오류 해결과 최적화,
4비트 양자화의 혈투들로 페이즈 4 마무리...
(이젠 AI의 헛발의 한계와 현시점의 한계도 부처 수준으로 되어버렸다.
나무아미타불.. ㅠ 처음부터 여기까지 약 한 달 반 소요.)
페이즈 5.
아무리 모델들을 gpu로 분배해도 트랜스포머스 모델 방식들이 안 맞는다...
cpu 이슈로 재부팅 또 시작 ㅠ
하... 계속 조사를 반복하여 gguf 방식의 새로운 발견!!
시도!!
모델이 안 돈다!!
llama cpp python이 필요하단다...
그건 또 뭔데? ㅆㅂ
AI에게 또 어드바이스 및 튜토리얼 요청. ㅠ
아무리 해도 안된다!!
계속 빌드 오류!!
실패!!
하루 삽질!!
조사 끝에
쿠다 툴킷 12.1,
vs2019,
파이썬 311 버전들이 호환성이 좋다는 소문을 들었다~!!
빌드 성공~~
한글 윈도에서 이틀 만에!!
(변수 정리, 프로그램들 재설치 등등 많은 삽질 동반.ㅠ)
근데... 쿠블라스가 떠야 더 좋단다.
응??
쿠블라스..?? 좋은 거면 해야지!! (역시 인간의 욕심은 끝이 없습니다.ㅠ)
또 삽질 끝에 완벽히 성공!!
CUDA : ARCHS = 750, USE_GRAPHS = 1, PEER_MAX_BATCH_SIZE = 128
CPU : SSE3 = 1, SSSE3 = 1, AVX = 1, AVX2 = 1, F16C = 1, FMA = 1
LLAMAFILE = 1, OPENMP = 1, REPACK = 1
터미널에서 파이썬 확인 값들이다.
빌드할 때 반드시 옵션을 잘 줘야 한단다...ㅠ
혹시 삽질 각오할 윈도 유저를 위해 설정 값 남긴다.
set CMAKE_ARGS=-DGGML_CUDA=ON -DGGML_CUBLAS=ON -DCUDA_ARCHITECTURES=75
복붙~!!
(75는 NVIDIA GeForce RTX 2060 SUPER 8GB의 아키텍 번호이다. 다른 그래픽 카드 아키텍 번호는 알아서 찾기를 바란다. 참고로 AI한테 물어보면 알려준다. ㅋㅋ)
이렇게 또 페이즈 5를 마무리... 이제 완벽 준비!!
페이즈 6.
On-demand loading & memory manager로 최적화
llm llama-3.2-Korean-Bllossom-3B-gguf-Q4_K_M.gguf,
korean-emotion-kluebert-v2는 동시 Vram 상주!!
안 쓰면 대기!!
Qwen2-VL-2B-Instruct-Q4_K_M.gguf,
LCM_Dreamshaper_v7 멀티 모달들은 온디맨드 로드로 스위칭
(어쩔 수 없다. 로딩 시간은 참자.ㅠ)
빠르다~ 재부팅도 안된다~ 사용률이 전이랑 비교도 안되게 여유롭다~~
성취감 Gooooood!!
사용량이 여유롭니 또 욕심난다~~ 언어 모델을 높이자!! (인간의 욕심은 정말 끝이 없다.)
페이즈 7.
언어 모델 업그레이드를 위한 새로운 전략 시작!!
언어 모델들을 테스트하기 위한 벤치마크 툴 찾기!!
젠장.. 내가 원하는 것들은 없다. ㅠ
AI한테 만들어 달라고 해야지~
3일 동안 ai 달달 볶아서 또 삽질하며 완성했다.
PKC 벤치마크 툴 MARK 완성~!!
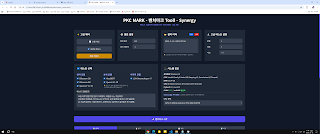
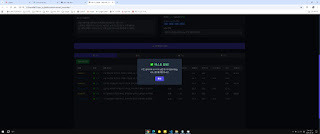
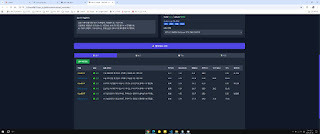



cuda 상세 옵션 값, 쿠블라스 표기, 각 하드웨어 사용량, 전력, 온도, 토큰 값 속도 등등
개인이 사용하기에는 좀 많이 욕심부린 느낌이다. ㅋㅋㅋ
이로써 모델 선별 끝!!
llama-3-Korean-Bllossom-8B-Q4_K_M으로 업그레이드하기로 확정!!ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
내 사양에서 돌아가냐고??? 아직 나도 몰라~~ 현재 진행 중인 프로젝트니~~
백엔드랑 프런트 분리하고 테스트해야 한다!!
여기까지가 PKC의 약 두 달 남짓 가량의 긴 여정의 중간보고이다.
이 글을 쓰며 나도 내가... 미친놈인 거 같아!!!!!!!!!!ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
이 글을 혹시라도 보는 사람들이 있어서 "나도 가능할까??"라는 도전 의식이 들어서
클라우드 기반 대화형 AI를 활용을 하든 협업을 하든
반드시 꼭 봐야 할 글귀 하나가 있다...
-- AI는 실수를 할 수 있습니다. 중요한 정보는 재차 확인하세요. --
다음 장에서 봐요~ 언제가 될지 모르지만ㅋ
PKC AI MARK 프로젝트 - RTX 2060 8GB로 로컬 멀티 모달 AI 구축 성공기
'AI-ONE' 카테고리의 다른 글
| 8GB VRAM으로 로컬 LLM 멀티모달 시스템 구축기_01 (0) | 2026.01.04 |
|---|---|
| 로컬 올인원 AI 시스템 (로컬 멀티모달 AI) (0) | 2025.11.15 |
| Phase 3: PKC AI MARK CSI: 코드 수사대 - 디지털 포렌식 리포트 (5) | 2025.09.25 |
| AI MARK 파일 구조 완전분석: 핵심 파일과 역할 정리 + 활용 팁 (0) | 2025.09.25 |
| Phase 2: 시스템 개선 끝판왕! AI MARK 최종 보고서로 본 안정성 & 성능 개선 과정 (0) | 2025.09.25 |