PKC AI-ONE 시스템 구축 튜토리얼_01
1. 들어가며
이 글은 AI를 활용해 작성되었다.
스크린샷이나 실제 시연 영상은 지금은 귀찮아서 생략했으며,
필요해지면 언젠가(?) 추가할 예정이다. 😄
로컬 LLM 이야기를 하면 흔히 이런 전제가 따라옵니다.
- VRAM 16GB 이상은 있어야 한다.
- 멀티모달은 서버급 GPU에서만 가능하다.
- RAG까지 붙이면, 개인 PC로는 무리다.
하지만 PKC AI-ONE은 다릅니다.
이 시스템은 8GB VRAM 단일 GPU 환경에서:
- 대화형 LLM
- 문서 기반 RAG
- 이미지 이해(VLM)
- 이미지 생성
- 세션/로그/감정 분석
을 하나의 로컬 시스템으로 통합해 운용하는 것을 목표로 설계되었습니다.
이 문서는 제가 실제로 사용 중인 PKC AI-ONE 시스템 구조와 모델 구성, 그리고 처음부터 직접 구축하는 방법을 튜토리얼 형식으로 정리한 기록입니다.
팁: 나도 만들고 싶은데 못 하겠다... 겁부터 난다... 하시는 분들은,
이 글을 ai에게 분석 시켜서 구현하는 아주 편하고 좋은 방법이 있습니다.
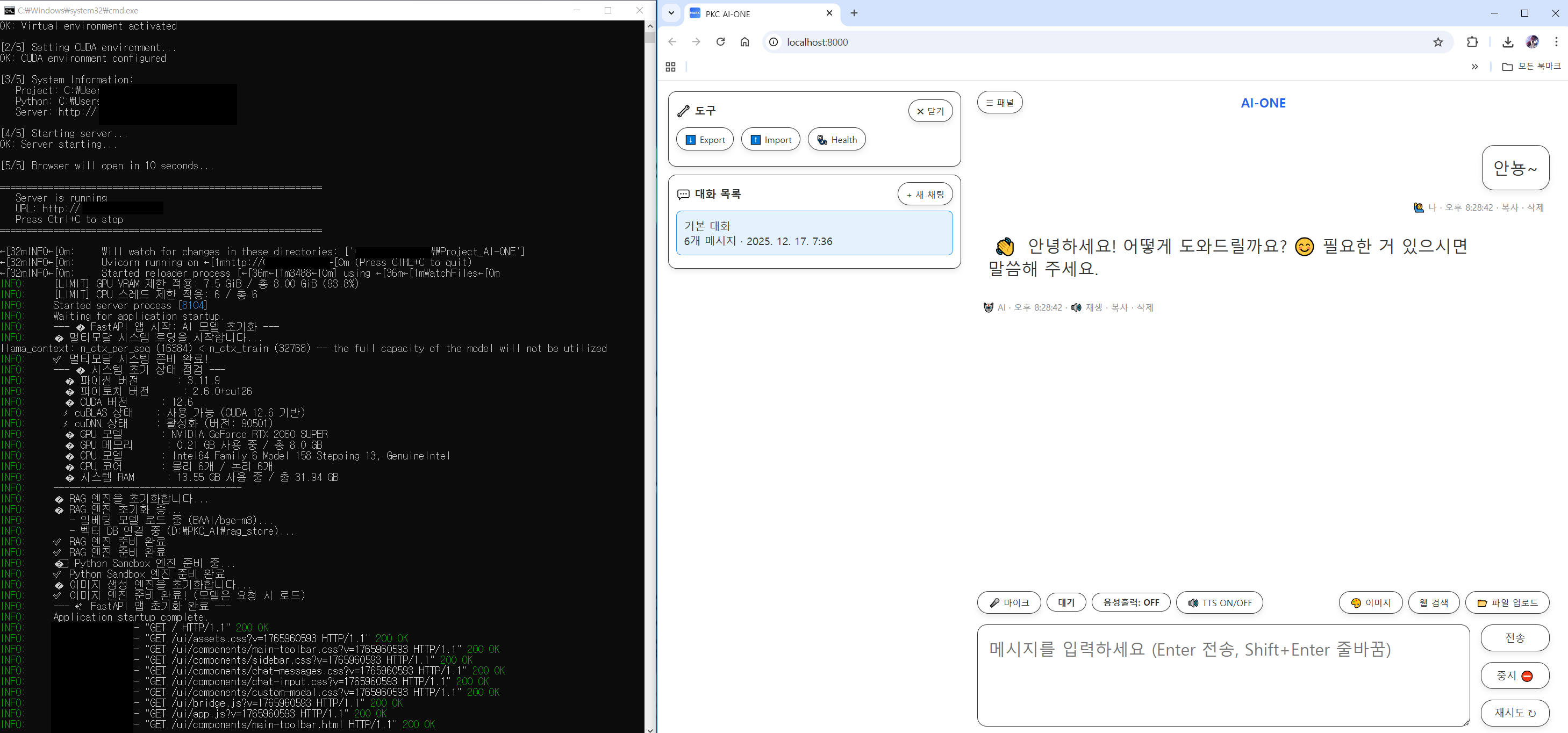
2. PKC AI-ONE 시스템 개요
2.1 시스템 한 줄 요약
브라우저 기반 UI + FastAPI 서버 + GGUF LLM + RAG + 멀티모달을 VRAM 스왑 전략으로 묶은 로컬 AI 시스템
2.2 핵심 설계 철학
- 오픈소스 모델들로 자유롭게, 무료로 만든다.
- 항상 하나의 무거운 모델만 VRAM에 올린다.
- 멀티모달은 "동시"가 아니라, "전환"으로 해결한다.
- UI는 가볍게, 로직은 서버에 집중한다.
- 모든 데이터는 로컬에 저장한다.
3. 사용 중인 모델 구성
아래는 PKC AI-ONE에서 실제로 로드하는 모델/파일명 기준으로 정리했습니다. (GGUF는 파일명에 양자화(Quant) 방식이 함께 표기됩니다.)
3.1 언어 모델 (LLM)
- 모델: EXAONE-3.5-7.8B 한국어 전용
- 로딩 방식: llama.cpp (GGUF)
- 파일 경로(예시):/models/EXAONE-3.5-7.8B/EXAONE-3.5-7.8B-Q5_K_M.gguf
- 양자화(Quant): Q5_K_M
- 역할: 메인 대화 생성, 추론, 코드 작성
- 특징:
- SSE 스트리밍 토큰 출력
- 멀티모달 작업(이미지 분석/생성) 시 VRAM 확보를 위해 언로드/리로드 대상
선택의 이유
이 모델은 단순히 "유명해서" 선택한 것이 아니다.
직접 개발한 PKC Mark 벤치마크 툴을 사용해, 동일한 프롬프트 세트와 작업 유형(대화, 요약, 추론, 코드)을 기준으로 여러 후보 모델을 반복 테스트했다.
그 결과, 내 환경(8GB VRAM, 단일 GPU) 에서 출력 품질, 응답 안정성, 토큰 생성 속도의 균형이 가장 우수한 모델이 EXAONE-3.5-7.8B였다.
3.2 이미지 이해 모델 (VLM)
- 모델: Qwen3-VL-4B
- 로딩 방식: llama.cpp (GGUF)
- VLM 본체 GGUF:/models/Qwen3-VL-4B/Qwen3-VL-4B-Q5_K_M.gguf
- 양자화(Quant): Q5_K_M
- mmproj(비전 프로젝터) GGUF:/models/Qwen3-VL-4B/mmproj-BF16.gguf
- 정밀도: BF16
- 역할: 이미지 설명/분석, 시각적 질의응답(VQA)
- 특징:
- 필요할 때만 로드 → 분석 완료 후 즉시 언로드
- 8GB VRAM 환경에서 LLM과 동시 상주 대신 “전환(스왑)” 방식으로 운용
선택의 이유
VLM 역시 PKC Mark로 여러 크기의 모델을 테스트했다.
그 결과 4B급이 VRAM 사용량 대비 인식 정확도가 가장 합리적인 지점이었고, Q5_K_M 양자화에서도 텍스트·객체 인식 품질 저하가 크지 않았다.
이 조합은 "항상 상주"가 아닌 "필요 시 호출" 구조에 가장 적합했다.
3.3 임베딩 모델 (RAG)
- 모델: BAAI/bge-m3
- 실행 위치: CPU 전용(의도적으로 GPU 미사용)
- 역할: 문서 임베딩, 의미 검색(semantic search)
- 특징:
- VRAM 사용 0
- ChromaDB(Persistent)와 결합해 로컬 벡터 저장소 구성
3.4 감정 분석 모델
- 모델 디렉터리:/models/korean-emotion-kluebert-v2
- 로딩 방식: Transformers
- 역할: 대화 감정 라벨링(로그/통계용)
- 특징:
- 채팅 품질보다 “대화 기록 분석/시각화” 목적에 가깝게 사용
3.5 이미지 생성 모델
- 모델: SD 3.5 Medium (GGUF 기반 로딩)
- 모델 ID/경로(예시):/models/SD-medium/sd3.5_medium-Q5_1.gguf
- 양자화(Quant): Q5_1
- 역할: 텍스트 → 이미지 생성
- 특징:
- 생성 작업 중에는 LLM을 언로드해 VRAM 확보
- 생성 결과는 base64로 반환해 UI에서 바로 렌더링
선택의 이유
이미지 생성 모델은 품질과 VRAM 소모의 타협이 가장 중요한 영역이다.
PKC Mark 테스트 결과, Q5_1 양자화가 8GB VRAM에서 안정적으로 동작하면서도 디테일 손실이 과하지 않은 최저선이었다.
고해상도·대량 생성을 포기하는 대신, "로컬에서 즉시 생성 가능한 품질"을 기준으로 선택했다.
4. 사용 환경 & 개발 환경
4.1 실제 사용 중인 하드웨어 환경
PKC AI-ONE은 아래 단일 PC 환경에서 실제 운용 중이다.
- 프로세서(CPU): Intel(R) Core(TM) i5-9600K @ 3.70GHz (6코어 6스레드)
- 메모리(RAM): 32GB DDR4
- 그래픽 카드(GPU): NVIDIA GeForce RTX 2060 SUPER (VRAM 8GB)
- 저장소: NVMe SSD
이 구성은 서버나 워크스테이션이 아닌, 비교적 흔한 데스크톱 환경이다.
4.2 개발 환경 (Software Stack)
- 운영체제: Windows 10
- Python: 3.10.x
- 서버 프레임워크: FastAPI + Uvicorn
- LLM/VLM 런타임: llama.cpp (GGUF)
- 임베딩/RAG: Sentence-Transformers + ChromaDB (Persistent)
- DB: SQLite
- Frontend: HTML / CSS / Vanilla JavaScript
개발 환경 역시 특수한 설정 없이, 로컬 개발자가 재현 가능한 구성을 유지하는 것을 목표로 했다.
4. 전체 아키텍처 구조
4.1 구성 요소
- Frontend: HTML / CSS / Vanilla JS
- Backend: FastAPI (Python)
- DB: SQLite + JSONL 로그
- Vector DB: Chroma (Persistent)
4.2 데이터 흐름
- 사용자가 브라우저에서 입력
- SSE 기반으로 서버와 스트리밍 통신
- 서버에서:
- RAG 검색
- 프롬프트 구성
- 모델 로드 / 언로드 제어
- 결과를 실시간으로 UI에 반영
5. 프로젝트 폴더 구조
PKC_AI_ONE/
├─ chat.py # FastAPI 메인 서버
├─ rag_engine.py # RAG 처리 엔진
├─ image_engine.py # 이미지 생성 엔진
├─ sandbox.py # 코드 실행 샌드박스
├─ settings.py # 설정 파일
├─ start_server.bat # 실행 스크립트
│
├─ index.html
├─ app.js
├─ bridge.js
├─ assets.css
│
├─ ui/
│ ├─ sidebar.html
│ ├─ chat-input.html
│ ├─ chat-messages.html
│ └─ ...
│
└─ data/
├─ rag_db/
├─ logs/
└─ uploads/
6. 8GB VRAM 핵심 전략: VRAM 스왑
6.1 문제
- LLM + VLM + 이미지 생성 모델을 동시에 올릴 수 없음
6.2 해결 전략
- VRAM_GUARD_SEMAPHORE로 동시 실행 제한
- 작업 유형에 따라 모델 전환
예시
- 채팅 중 → LLM 로드
- 이미지 분석 요청 → LLM 언로드 → VLM 로드
- 이미지 생성 요청 → LLM 언로드 → 생성 모델 로드
이 방식으로 8GB VRAM에서도 멀티모달 운용이 가능하다.
7. 채팅 시스템 (SSE 스트리밍)
7.1 왜 SSE인가
- WebSocket보다 단순
- HTTP 기반
- 토큰 단위 스트리밍에 최적
7.2 동작 방식
- /chat_stream_sse_fetch 엔드포인트
- data: {...} 형태로 토큰 전송
- [DONE] 시 종료
8. RAG (문서 기반 응답)
8.1 문서 업로드
- 텍스트 파일 업로드
- 자동 청킹
- 임베딩 후 ChromaDB 저장
8.2 질의 시
- 사용자 질문 임베딩
- 유사 문서 검색
- 프롬프트에 참고자료로 삽입
9. 세션 & 로그 시스템
9.1 저장 항목
- 세션 메타데이터
- 대화 로그
- 감정 분석 결과
- 의도/키워드
9.2 장점
- 대화 복원 가능
- 학습 데이터 추출 가능
- 파인튜닝용 데이터 생성 가능
10. 이 시스템으로 할 수 있는 것
- 완전 로컬 AI 어시스턴트
- 문서 기반 지식 시스템
- 이미지 분석/생성 도구
- 연구/개발 보조 AI
- 개인용 GPT 대체 환경
11. 마치며
PKC AI-ONE은 "고사양 장비가 없어도 가능한 AI 시스템"을 목표로 한다.
8GB VRAM이라는 제약은 오히려:
- 구조를 단순하게 만들고
- 자원 사용을 정교하게 설계하게 만들고
- 진짜 필요한 기능에 집중하게 했습니다.
이 문서가 로컬 AI 시스템을 직접 만들고 싶은 사람에게 하나의 현실적인 출발점이 되길 바랍니다.
(언제가 될지 모르지만...
다음 편: 실제 코드 분석 & 단계별 구현 튜토리얼)
'AI-ONE' 카테고리의 다른 글
| 로컬 올인원 AI 시스템 (로컬 멀티모달 AI) (0) | 2025.11.15 |
|---|---|
| Phase 3: PKC AI MARK CSI: 코드 수사대 - 디지털 포렌식 리포트 (5) | 2025.09.25 |
| AI MARK 파일 구조 완전분석: 핵심 파일과 역할 정리 + 활용 팁 (0) | 2025.09.25 |
| Phase 2: 시스템 개선 끝판왕! AI MARK 최종 보고서로 본 안정성 & 성능 개선 과정 (0) | 2025.09.25 |
| Phase 1: 2개월간의 AI MARK 여정: 시행착오, 배운 것, 앞으로 방향 (4) | 2025.09.25 |